Needles in the Haystack: Correcting Errors in RISM’s Music Incipits
Thursday, April 25, 2024
While RISM has been a showcase for large-scale cooperation from its very foundations over seventy years ago, this predominantly affected the cataloguing of primary sources all around the globe by our international working groups. In the past few years, however, the RISM Editorial Center has been increasingly involved in institutional cooperations that seek to further develop the cataloguing infrastructure and enhance our data overall. A case in point is the incipit project launched in late 2021 to improve the quality of the well over two million music incipits stored in RISM’s more than 1.5 million source descriptions. In this large-scale effort – besides the Editorial Center and the RISM Digital Center as the usual suspects, so to speak – Carlo Licciulli from the Centre for Digital Music Documentation (CDMD) of the Academy of Sciences and Literature in Mainz plays a crucial role, thanks also to the generous involvement of the Saxon State and University Library Dresden (SLUB). From the organizational point of view, the project is run under the auspices of NFDI4Culture.
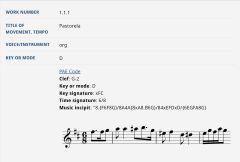
The idea to target specifically the music incipits was given by a significant improvement of the Muscat application used for RISM cataloging, thanks to which colleagues adding music incipits to their source descriptions can not only see a visual rendering of the music right away, but also receive notifications from Verovio (the software developed by the RISM Digital Center that runs in the background) if their code might not fully confirm to the guidelines. While this functionality makes cataloging much easier and guarantees that the incipits entered now are of consistently higher quality, the red validation messages also appear if one opens a record encoded before the introduction of this new feature, while one could barely expect our working groups to return to these incipits and systematically revise the Plaine & Easie Code entered several years (or even decades) ago. It is this older dataset that our incipit project deals with, seeking not only to catch the errors but also to identify ways to correct them, preferably with carefully designed scripts, since making corrections by hand is extremely time-intensive, and must therefore be restricted to the most problematic cases.
In the initial phases, general features like clefs, key and time signatures, or the numbering of the incipits were considered, but by now we are in the middle of the haystack, so to speak, looking closely at oddly placed accidentals, unclosed (or unopened) beams, as well as a wide range of out-of-place characters (that have no meaning in Plaine & Easie). In the last category, some inconsistencies are easy to discover and correct (e.g., when a text originally meant for another field was erroneously entered in the incipit code), while typographic errors often prove difficult to amend with any certainty, unless they prove to be more or less systematic (like the number 7 standing in place of a bar line, since the cataloger – sitting before a keyboard with German layout – forgot to press Shift at the same time). Of greater relevance is the identification of a certain couleur locale, as it were; e.g., when a cataloger (or even several members of the same working group) tended to encode a feature in a somewhat irregular way, for such idiosyncrasies – once discovered – may allow for a systematic correction with a script. Overall, the daily work with these music incipits is fascinating, and proves to be a textbook example of how editors (who understand the wider context of the musical sources and can thus reconstruct what an erroneous encoding likely corresponded to in the original) and IT experts (who analyze diverse aspects of the data and eventually write the scripts for correction) must work hand in hand in order to identify the best way of correction for each incipit.
As part of this important initiative, we have already undertaken close to 150,000 corrections by script and about 6,000 by hand, but there is still much ground to be covered and – given the complexity of the issues identified – one must watch one’s every step most carefully. That said, by now our users have hopefully experienced that the number of inconsistencies in our music incipits have decreased, while the most important goal of the project is an even more ambitious one: by cleansing the Plaine & Easie encodings we are ensuring that the music incipit searches (whether run in the RISM Catalog or on RISM Online) prove ever more effective, returning as many and as relevant hits as only possible. This should not only please our users, among whom the incipit search is one of the most popular features offered by RISM’s vast online database, but should in the longer run also allow us to reduce the number or anonymous, or falsely attributed sources, by matching these with better documented source records on the basis of their similar music incipits.
Image: Incipit in RISM’s cataloging program, RISM ID no. 390000007
Share Tweet EmailCategory: New at RISM
